
Le cloud est partout, on en entend parler à tous les coins de rue. Il est fort probable que vous ou votre entreprise utilisiez de près ou de loin un service cloud (AWS, Google Cloud, pour ne nommer que ces deux-là).
Si vous l’utilisez intensément (plusieurs machines qui tournent en continu), vous vous êtes peut-être intéressé à l’auto-scaling.
L’auto-scaling permet d’ajouter ou d’enlever des machines en fonction du besoin, en quasi temps-réel. Par exemple lorsque le traffic de vos utilisateurs augmente drastiquement et que vos serveurs sont sous l’eau, l’auto-scaling permet de rajouter des machines afin de libérer la charge des serveurs existant, diminuer le temps de réponse pour vos utilisateurs et garder la qualité du service que vous proposez.
Sans auto-scaling le problème inverse existe également : en période creuse, vos machines n’ont rien à faire, mais vous les payez quand même.
Cela est bien sûr bénéfique pour la plateforme Cloud que vous utilisez, mais moins pour vous.
Chez Adenlab nous utilisons Google Cloud, et nous utilisons bien sûr l’auto-scaling. Le besoin est le suivant : la nuit, nous importons les data de vos comptes Google Ads, Analytics, Amazon, Bing, etc.
Nous apprenons sur ces data (machine learning), calculons les nouveaux bids de vos produits, et nous les mettons à jour sur les plateformes concernées. Et nous faisons encore beaucoup d’autres choses ! Tout cela chaque nuit.
Chacune de ces opérations a des besoin spécifiques en volume et puissance des machines. Nous avons par exemple quelques machines puissantes pour le machine learning, et beaucoup de machines peu puissantes pour mettre à jour les enchères.
Avoir autant de machines à temps plein serait une perte nette de budget, puisque la plupart n’ont rien à faire pendant la journée. Nous regroupons donc ces machines en fonction de leur type (puissance, etc.) dans des groupes, appelés Auto-Scaling Groups.
Auto-Scaling Groups
Les groupes d’auto-scaling (Auto-scaling groups, ASG) permettent de regrouper des machines de même type sous une même politique d’auto-scaling.
Par défaut dans Google Compute Engine (GCE), vous pouvez choisir de scaler en fonction de l’utilisation CPU ou mémoire. En utilisant l’outil de monitoring Stackdriver, vous pouvez créer des métriques personnalisées afin d’augmenter ou de diminuer le nombre de machines.
Malheureusement il est impossible de scaler automatiquement un ASG à zéro, c’est-à-dire de couper toutes les machines du groupe. Cela est assez logique puisqu’en l’absence de machine nous ne recevrions plus aucune métrique (CPU ou autre) amenant à re-scale de nouveau.
Dans notre cas, beaucoup de nos machines travaillent à des moments précis dans la journée, généralement pendant 8 à 10 heures d’affilée, et n’auront plus rien à faire pour le reste de la journée. Voici un exemple d’exécution de notre politique d’auto-scaling :
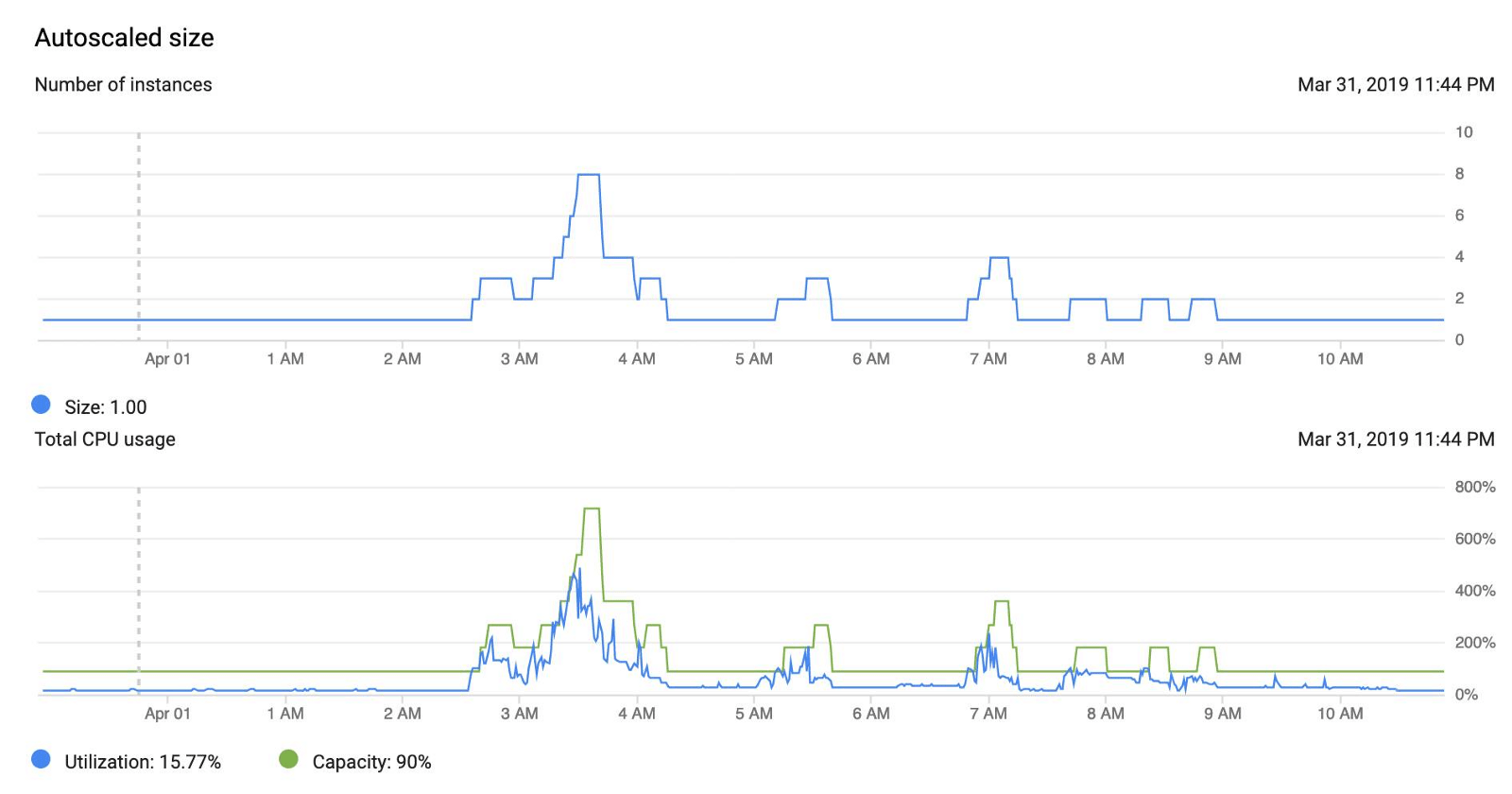
Auto-scaler à zéro machine
On aimerait bien sûr éviter d’avoir à payer pour une machine inutile. Nous allons voir qu’il y a un moyen d’avoir zéro machine tout en ayant un système de scaling automatique.
Il y a cependant un pré-requis : il nous faut un moyen de savoir quand est-ce qu’il est nécessaire de scale up de nouveau.
Chez Adenlab nous utilisons une taskqueue (MRQ) pour nos tâches récurrentes. MRQ nous permet d’aiguiller nos jobs vers des worker groups spécifiques, en fonction de la queue et/ou de la tâche elle-même. Chaque worker group est lié à un ASG, nous avons donc ici une métrique claire : pour un ASG donné, avons-nous des jobs en attente ?
Avec tout ça nous pouvons utiliser la structure d’ASG suivante :
Une petite (lire: pas chère) machine qui sera toujours up (pas auto-scalée)
Un ou plusieurs ASG, sans politique d’auto-scaling
En créant un ASG sans politique d’auto-scaling, GCE nous laissera bien scale à zéro machine si nous le voulons. Sur notre petite machine nous aurons un script qui tournera toutes les 5 minutes et qui vérifiera pour chaque worker group MRQ s’il y a des jobs à traiter.
Si c’est le cas, le script créera une politique d’auto-scaling pour le worker group concerné et le fera un premier scale-up à 1 machine. L’auto-scaler pourra ajouter des machines supplémentaires si besoin, en fonction de la métrique de base configurée (dans notre cas, l’utilisation CPU).
Ecrivons une tâche MRQ pour ce script. Déjà les imports nécessaires :
from mrq.task import Task
from google.oauth2 import service_account
from googleapiclient import discovery
import time
import rePremièrement, nous devons configurer quelques paramètres concernant GCP :
class ScaleUp(Task):
project_name = "name of your GCP project"
zone = "europe-west1-c" # adapt your zone here
service_account_path = "service_account_credentials.json"
# groups that are not concerned by this task
groups_to_skip = ("group1",)Ajoutez à groups_to_skip les worker groups qui ne devraient pas être auto-scalés : ajoutez au moins le groupe de la machine qui dépilera cette tâche.
Maintenant écrivons la méthode principale de notre tâche :
def run(self, params):
credentials = service_account.Credentials
.from_service_account_file(
self.service_account_path
)
self.service = discovery.build(
"compute",
"v1",
credentials=credentials,
cache_discovery=False
)
# We need to have a way to know what we want our different
# autoscaling policies to be.
# We could store them in a DB and fetch them here,
# so that it is shared with our Ansible playbooks for instance.
# For simplicity here we'll just hardcode them here:
self.autoscaler_configs = {
"group2": {
"min_replicas": 1,
"max_replicas": 10,
"cooldown": 180,
"cpu_target": 0.80
},
"group3": {
"min_replicas": 1,
"max_replicas": 8,
"cooldown": 180,
"cpu_target": 0.90
}
}
# First we need to fetch existing ASGs
self.fetch_groups()
# Next we want to know which groups currently have an autoscaler
self.fetch_autoscalers()
# Check each groups and see if we should scale them up
self.check_groups()Voici comment récupérer les infos sur les ASG :
def fetch_groups(self):
self.groups = {}
request = self.service.instanceGroupManagers()
.list(
project=self.project,
zone=self.zone
)
while request is not None:
response = request.execute()
for asg in response['items']:
group_name = asg["baseInstanceName"]
self.groups[group_name] = {
"base_name": group_name,
"name": asg["name"],
"size": asg["targetSize"],
"link": asg["selfLink"]
}
request = self.service.instanceGroupManagers()
.list_next(
previous_request=request,
previous_response=response
)On hydrate self.groups avec les infos des ASGs. Pour plus d’infos sur la structure des ASGs, allez voir ici.
Maintenant jetons un oeil au code que nous utiliserons pour créer un autoscaler pour un worker group donné :
def create_autoscaler(self, group):
autoscaler_config = self.autoscaler_configs[group]
config = {
"target": self.groups[group]["link"],
"name": "%s-as" % group,
"autoscalingPolicy": {
"minNumReplicas": autoscaler_config["min_replicas"],
"maxNumReplicas": autoscaler_config["max_replicas"],
"coolDownPeriodSec": autoscaler_config["cooldown"],
"cpuUtilization": {
"utilizationTarget": autoscaler_config["cpu_target"]
}
}
}
operation = self.service.autoscalers().insert(
project=self.project,
zone=self.zone,
body=config
)
wait_for_operation(operation)Vous pouvez trouver le code de wait_for_operation dans cet exemple.
La dernière chose dont nous ayons besoin est une méthode pour scale up un ASG :
def scale_up(self, group, size=1):
if self.groups[group]["size"] > 0:
# Already scaled up
return
# Make sure we have an autoscaler
if not self.autoscalers.get(group):
self.create_autoscaler(group)
operation = self.service.instanceGroupManagers().resize(
project=self.project,
zone=self.zone,
instanceGroupManager=self.groups[group]["name"],
size=size
)
wait_for_operation(operation)La logique finale de notre tâche est assez simple :
def check_groups(self):
# Now we have everything we need for the actual task logic:
for group in self.groups:
if group in self.groups_to_skip:
continue
if self.should_scale_up(group):
self.scale_up(group)should_scale_down est la méthode qui doit contenir votre logique de scaling. Nous ne la fournissons pas ici, mais rappelez-vous que dans notre cas il s’agit de vérifier si nous avons des jobs en attente ou non.
Cette tâche est planifiée pour être exécutée toutes les 5 minutes. Cela est pratique pour notre cas d’usage car même si aucun job n’est en attente, un membre de l’équipe peut à tout moment exécuter une action qui entrainera la création d’un nouveau job.
On ne veut pas avoir à attendre trop longtemps avant que celui-ci soit démarré. Bien entendu pour toute action utilisateur qui crée des jobs et qui sont supposées obtenir une réponse rapidement, il nous faut une machine dédiée qui soit toujours up.
Dans la plupart des cas cependant il vaut mieux éviter d’avoir des tâches asynchrone pour les interactions utilisateurs qui ont besoin d’un feedback.
Nous pouvons donc maintenant scale up une machine quand on en a besoin et GCE prendra le relai s’il y en a besoin de plus. Mais nous avons aussi besoin d’un moyen de scale à zéro quand il n’y en a de nouveau plus besoin !
Pour cela nous avons une seconde tâche, exécutée toutes les 30 minutes, qui exécutera le même code que la première, à la différence qu’elle supprimera l’autoscaler et scalera à 0 machine s’il n’y a plus aucun job en attente.
Nous pouvons faire hériter notre nouvelle tâche de la précédente afin d’avoir à disposition les méthodes utiles pour communiquer avec GCP :
class ScaleDown(ScaleUp):Nous avons aussi besoin de quelques nouvelles méthodes pour pouvoir scale down :
def delete_autoscaler(self, group):
autoscaler = self.autoscalers[group]
operation = self.service.autoscalers().delete(
project=self.project,
zone=self.zone,
autoscaler=autoscaler["name"]
)
wait_for_operation(operation)
def scale_down(self, group):
if self.groups[group]["size"] == 0:
# Already scaled down
return
# Delete the autoscaler so that we can scale to zero machine
if self.autoscalers.get(group):
self.delete_autoscaler(group)
operation = self.service.instanceGroupManagers().resize(
project=self.project,
zone=self.zone,
instanceGroupManager=self.groups[group]["name"],
size=0
)
wait_for_operation(operation)
def check_groups(self):
for group in self.groups:
if group in self.groups_to_skip:
continue
if self.should_scale_down(group):
self.scale_down(group)Quand on sait qu’il n’y a plus aucun job en attente, on supprime l’autoscaler et on scale down complètement. De nouveau, should_scale_down contient la logique de scale down à implémenter.
Le côté positif de cette approche est que nous pouvons avoir plusieurs critères de scaling. Par exemple, afin d’éviter de scale up et down plusieurs fois de suite de manière trop rapprochée, on peut également vérifier qu’un certain temps s’est écoulé sans avoir de job créé avant de scale down.
Conclusion
Nous avons vu qu’en supprimant la politique d’autoscaling nous pouvons supprimer toutes les machines d’un groupe d’instance.
Nous avons écrit une tâche d’autoscaling qui utilise une logique custom pour savoir si un groupe devrait être up (1 machine) ou down (0 machine).
L’inconvénient est que nous devons avoir une machine séparée, toujours up et prête à dépiler notre tâche d’autoscaling.


